Overview
Analysis of the Paper “Negative Data Augmentation” (ICLR 2021)
- Arxiv: here
TLDR
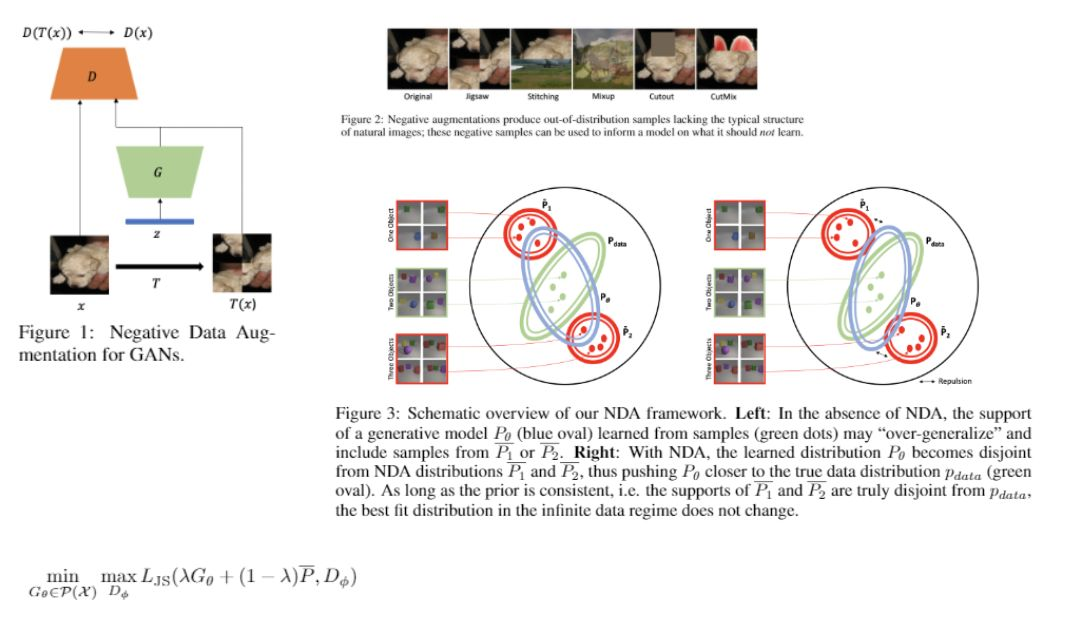
Summary
Very interesting paper about generative models
1. Introduction
A common failure mode for generative models, especially GAN, is they produce a significant amount of “false positives”: samples that are not realistic.
Why?
Using an analogy with physics, standard GANs are trained by enforcing a sort of attractive potential between the generator distribution and the true distribution samples, using the discriminator.
So we have
- \(P_{data}\) : Real Data Distribution
- \(P_{data}^{(n)}\) : Samples based representation of the Real Distribution, with \(n\) samples
- \(P_{\theta}\) : Generated Distribution
- \(D(P_{data}, P_{\theta})\) : Discriminator, expressing the attractive potential between the 2 distributions
- \(\{ \bar P_{1}, \bar P_{2}, ..., \bar P_{p} \}\) : Bad samples regions
The training can be imagined as using the attractive potential of \(D(\cdot, \cdot)\) to steer \(P_{\theta}\) towards \(P_{\theta}\)
This method is effective in increasing the True Positives (generated samples that seem realistic) altough a common failure mode is this also increases the False Positives (generated samples that are not realistic)
2. Problem Formulation
The bad samples distributions have been called \(\{\bar P_{i}\}_{i=1,...,p}\) and are represented in Fig.3 as red circles: it is possible to see in the left image the overlapping area between the \(P_{\theta}\) and \(\{\bar P_{i}\}_{i=1,...,p}\) representing the generated bad samples
The goal is to minimize this overlapping area
3. Solutions
3.1 Add more positive samples
Building a better samples based representation of the underlying real data distribution \(P_{data}^{(n)}\) meaning increasing the \(n\) number of samples, leads to convergence \(\lim_{n \rightarrow \infty} P_{\theta} = P_{data}^{(n)}\)
Unfortunately the \(n \rightarrow \infty\) is called the Infinite Data Regime and in practice we are very far from it so this theoretical guarantee is of no practical use
3.2 Add negative samples
Here is the idea suggested by the paper
Relying only on positive samples is too samples inefficient, meaning too many samples are needed to get good results in practice, so the idea is to change the Discriminator Term so that it can accept also negative examples that are related to a repulsive potential
So the combination of good samples attractive potential and bad samples repulsive potential should improve the samples efficiency of the training process
Typically in GANs a sample \(x\) can come from 2 distributions
-
\(x \in P_{data}^{(n)}\) : so \(x\) is a real data sample
-
\(x \in G_{\theta}\) : so \(x\) is a generated data sample
Here one more possibility is added
- \(x \in \bar P\) : so \(x\) is a bad a data sample
So recalling the convention about the binary classification problem of the Discriminator where 1=Real, 0=Fake then the energy terms are
-
\(x \in P_{data}^{(n)}\) => \(\log(D(x))\)
-
\(x \in G_{\theta}\) => \(\log(1 - D(x))\)
-
\(x \in \bar P\) => \(\log(1 - D(x))\)
Examples

Personal Comments
The 3.2 solution implies the following
-
changing the Discriminator Objective by the introduction of a new term
-
possibly reducing the Generator impact on the Discriminator and consequently the amount of gradient it will observe, since the Generator only gets the gradient when a generated sample is submitted, while the Discriminator always gets the gradient
This means if in general we have a function \(f(\phi, t; P_{data}^{(n)}, G_{\theta}, \bar P)\) that at each \(t\) training time outputs a sample from one of the 3 source distributions, making the decision as a function of \(\phi\) set of parameters, then this function can very well have a strong impact on the final performance
Also available on LinkedIn here